


Share this to








When it comes to multi-source data integration, there are two main schools of thought: the traditional data structure and the modern data flow.
The traditional data structure is based on bespoke connectors that ferry data from one source to another.
On the other hand, the modern data flow relies on a single central repository of data - often called a warehouse or lake. The modern data flow is the approach to data integrations that your company should take when choosing to use an Integration Platform as A Service
In this blog post, we'll take a look at the benefits of using a modern data flow for your multi-source integration.
The Modern Data Flow and the Data Industry's Digital Transformation
Digital transformation for organisations around the glove is in full swing. Companies are adopting new platforms and tools at an alarming rate. This influx of new technology has led to a complexity that was once unheard of in the data industry.
But all this change doesn't have to be a bad thing. By adopting a modern data flow, you can ensure the reliability and security of your data. With data at the core of your decision-making, you can stay ahead of the competition and lead the charge into the future.
The Traditional Data Flow.
The traditional data flow requires custom connectors to move data from one source system to another. This approach can be quite effective in certain scenarios, but it can also be more complex and costly when you need to move large amounts of data quickly or between multiple systems.

The Modern Data Flow.
What is the Modern Data Flow?
It is a model of data integration that uses a central repository - a warehouse or lake - as the source of truth. All information flows into the lake, is transformed or consolidated into the necessary shape, and sent back out to platforms that require it. In this way, it acts like a hub and spoke system. To make this model the best it can be, you should use existing ETL (extract, transform, load) and R-ETL (reverse extract, transform, load) services.
What is an ETL?
ETL stands for extract, transform, load. It is the process of taking data from a source platform (like HubSpot) and putting it into a repository, like Snowflake.
What is an R-ETL?
R-ETL stands for reverse extract, transform, load. This is the opposite of an ETL - you are taking data from your repository and sending it back out to other platforms that require it.
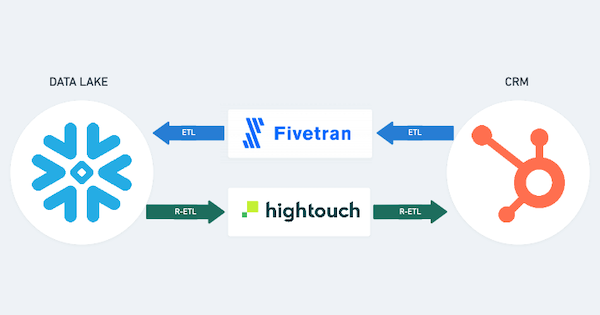
So why use a modern data structure?
Using the modern data flow model has many advantages over traditional methods of data integration. By using existing ETL and R-ETL services you can avoid needing custom connectors between each source and destination platform which saves time, money and effort.
- Existing compatibility - These services are built with a single function in mind - link two data sources. As such, they have an ever-growing list of built-in connectors. This means that there is a minimal chance of any incompatibility issues arising between the two data sources being linked.
- Support infrastructure - these are big brands, with dedicated support teams, online communities, and freely available documentation. This means that if any problems or questions arise, help is easily available.
- Robustness and Security - These services have a minimal chance of suffering any sort of outages, and are accredited with digital security. This means that your data is safe and secure when using these services.
- Flexibility and Accessibility - They’re easy to use! Want to add more data? Go ahead. Want to sync certain data, to a certain location, at a certain time? Sure thing. You’re also future-proofed for any potential changes to your tech. This means that you can be confident that these services will always meet your needs.
To learn more about The Modern Data Flow, check out this video explanation:



Considering a Multi-Source Integration
Eliminate complexity in your data structure.
Experience a single source of truth in your data with integrations that are secure, reliable, and flexible.
